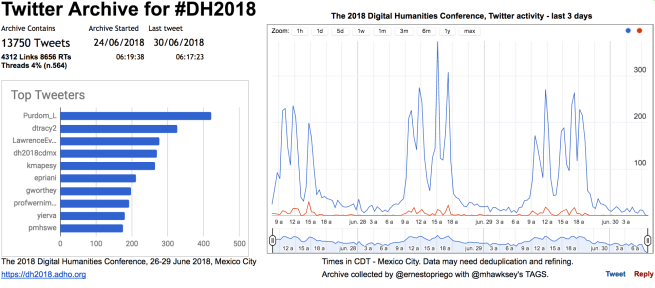
I collected an archive of #DH2018 tweets from accounts with at least 10 followers. The main quant summary is in the table below, which I also tweeted earlier:
I wanted to take a quick look at number of tweets per user_lang. “user_lang” filters the language that appears in the user twitter profile. (Please note “user_lang” is different from “lang”, which, when present, indicates a BCP 47 language identifier corresponding to the machine-detected language of the tweeted text).
Filtering the #DH2018 tweets archive by user_lang and then counting the number of tweets per user_lang gives us the following table:

The archive only collected tweets from acounts with at least 10 followers. The table above can be, just for fun, visualised as a simple bar chart, as a means to quickly show the difference in volume:

Please note the archive collects unique tweets including RTs, therefore it can be a unique tweet by a unique user who has been retweeted several times (or none) that contributes to the count or a given user_lang.
In other words, the counts above do not indicate there were x number of users whose Twitter profiles had x language code, but merely the number of tweets in this specific archive organised according to the user_lang code from the tweeter’s Twitter profile.
Therefore what this can possibly provide an indication of is of the over or under-representation of tweets from accounts whose Twitter profiles have specific language codes. It’s not that x number of tweets in the archive were in this or that language, nor that x number of tweeters using the hashtag speak this or that language.
What becomes apparent is that an overwhelming majority of accounts with tweets in the archive have ‘en’ as the language code in their Twitter profiles; it is interesting that, in the archive, only one tweet was collected by an account with ‘es-MX’ as the language code in its Twitter profile.
One must also take into account that often ‘en’ is or might be the default user_lang code in Twitter profiles.
I still need to go back to my archives from previous years, but it does look like that in spite of the usual over-representation of the ‘en’ user_lang code, at least there is a diversity of user_lang in the archived tweets, with ‘es’ in second place.
Once I refine and anonymise the data I will be depositing the source data for this post.
*This blog post was typed quickly, typos and wonky syntax might have remained.

One thought on “Tweets per user_lang in a #DH2018 archive”
Comments are closed.