
#DH2017 starts today in Montreal. The theme is “Access/Accès”. Details in the hyperlink. I wish I were there!
I am sure the tweetage will exceed the limits of my poor Google spreadsheet, but as it’s become kind of customary I am attempting to collect as many tweets with the conference hashtag as possible.
Using Martin Hawksey’s TAGS, here’s what the archive looks like as of 6:35:05 AM Montreal time of the first official day (8 August 2017):

As of 9 August 2017, 6:11:33 AM Montreal time

As of 10 August 2017, 6:07:45 AM Montreal time
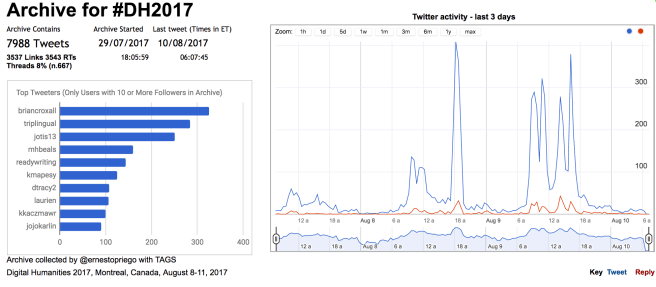
As of 11 August 2017, 7:12:46 AM Montreal time

As of 12 August 2017, 03:11:57 AM Montreal time. (I would have liked to take this screenshot later but I would not be online at that time. Considering the conference had finished by then it will do),

As of 13 August 2017, 05:50:54 AM Montreal time

On 9 August do note the hashtag went nuclear being spammed, particularly with annoying ‘trending topics’ tweets, so data could do with some refining. However it does not look, at a quick glance, that spamming was serious. With more time further on and once I have closed the collection I could take a closer look and give an indication of the extent of the spamming. In any case please note as always the counts I am presenting are merely indicative, numbers are not meant to be taken at face value and no inherent quality or value judgements should be inferred from the volumes reported.
As I often state the data presented is the result of the collection methods employed, different methods are likely to present different results.
Note that this time only tweets from users with at least 10 followers are being collected. For the purpose of the archive, retweets count as tweets (this means not every tweet contains ‘original’ content).
It has been assumed that those scholars or scholarly organisations tweeting publicly from public accounts at very high volumes from an international conference do expect to get noticed by the international community for for their tweetage with the hashtag and therefore are giving implicit consent to get noted by said community for scholarly purposes; if anyone opposes to their username appearing in one of the ‘Top Tweeters’ bar charts above please let me know and I can anonymise their username retrospectively if that helps.
This is the first year I manage to archive a more or less complete set. On the one hand it helps that TAGS has improved, that I was able to be collecting and monitoring the collection in real time, and that I set the limit of a minumum of 10 followers for accounts to be collected. It also helped I did not start collecting to far back in advance as I sometimes have done.
I will be depositing a dataset of Tweet ID’s and timestamps, which is the source data for the charts embedded here, next week.
Speaking of “Access/Accès”, here’s a recent post I wrote about access and license types in a set of articles from the Journal of Digital Scholarship in the Humanities. In case you missed it (you probably did), it might be of interest given this year’s theme.

You must be logged in to post a comment.