As everyone in some way aware of UK higher education knows, the results from the REF 2014 were announced in the first minute of the 18th of december 2014. Two main hashtags have been used to refer to it on Twitter; #REF and the more popular (“official”?) #REF2014.
There’s been of course other variations of these hashtags, including discussion about it not ‘hashing’ the term REF at all. Here I share a quick first look at a sample corpus of texts from Tweets publicly tagged with #REF2014.
This is just a quick update of a work in progress. No qualitative conclusions are offered, and the quantitative data shared and analysed is provisional. Complete data sets will be published openly once the collection has been completed and the data has been further refined.
The Numbers
I looked at a sample corpus of 23,791 #REF2014 Tweets published by 10,654 unique users between 08/12/2014 11:18 GMT and 18/12/2014 16:32 GMT.
- The sample corpus only included Tweets from users with a minimum of two followers.
- The sample corpus consists of 1 document with a total of 454,425 words and 16,968 unique words.
- The range of Tweets per user varied between 70 and 1, with the average being 2.3 Tweets per user.
- Only 8 of the total of 10,654 unique users in the corpus published between 50 and 80 Tweets; 30 users published more than 30 Tweets, with 9,473 users publishing between 1 and 5 Tweets only.
- 6,585 users in the corpus published one Tweet only.
A Quick Text Analysis
Voyant Tools was used to analyse the corpus of 23,791 Tweet texts. A customised English stop words list was applied globally. The most frequent word was “research”, repeated 8,760 times in the corpus; it was included in the stop-word list (as well as, logically, #REF2014).
A word cloud of the whole corpus using the Voyant Cirrus tool looked like this (you can click on the image to enlarge it):
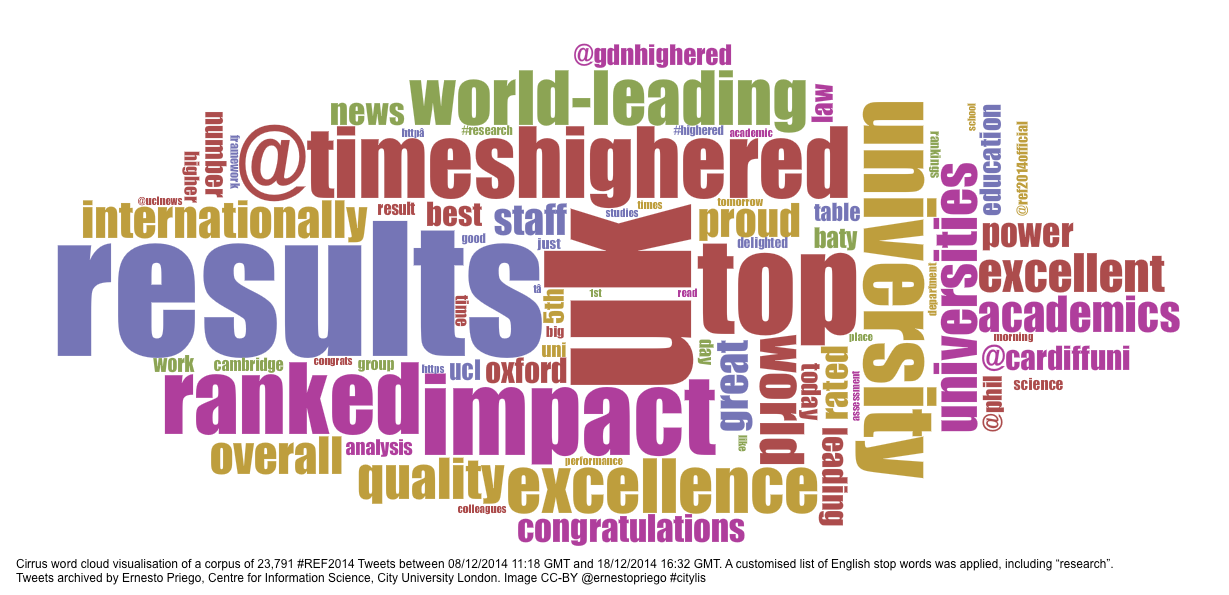
#REF2014 Top 50 Most frequent words so far
| Word | Count |
| uk | 4605 |
| results | 4558 |
| top | 2784 |
| impact | 2091 |
| university | 1940 |
| @timeshighered | 1790 |
| ranked | 1777 |
| world-leading | 1314 |
| excellence | 1302 |
| universities | 1067 |
| world | 1040 |
| quality | 1012 |
| internationally | 933 |
| excellent | 931 |
| overall | 910 |
| great | 827 |
| staff | 827 |
| academics | 811 |
| proud | 794 |
| congratulations | 690 |
| rated | 690 |
| power | 666 |
| @cardiffuni | 653 |
| oxford | 645 |
| leading | 641 |
| best | 629 |
| news | 616 |
| education | 567 |
| 5th | 561 |
| @gdnhighered | 556 |
| @phil_baty | 548 |
| ucl | 546 |
| number | 545 |
| law | 544 |
| today | 536 |
| table | 513 |
| analysis | 486 |
| work | 482 |
| higher | 470 |
| uni | 460 |
| result | 453 |
| time | 447 |
| day | 446 |
| cambridge | 430 |
| just | 428 |
| @ref2014official | 427 |
| group | 422 |
| science | 421 |
| big | 420 |
| delighted | 410 |
Limitations
The map is not the territory. Please note that both research and experience show that the Twitter search API isn’t 100% reliable. Large tweet volumes affect the search collection process. The API might “over-represent the more central users”, not offering “an accurate picture of peripheral activity” (González-Bailón, Sandra, et al. 2012). It is not guaranteed this file contains each and every Tweet tagged with the archived hashtag during the indicated period. Further dedpulication of the dataset will be required to validate this initial look at the data, and it is shared now merely as an update of a work in progress.
References

One thought on “The REF According to Twitter: A #REF2014 Update (18/12/14 16:28 GMT)”
Comments are closed.